DFA Anatomy
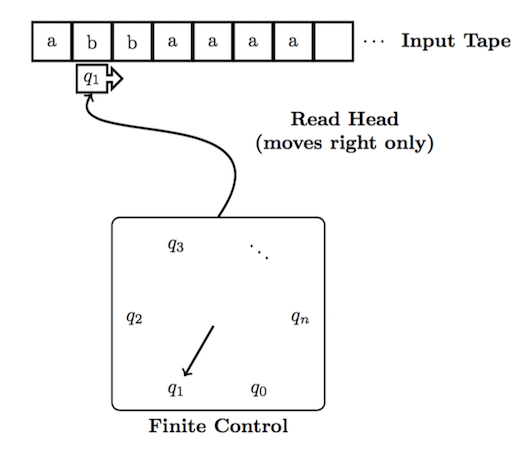
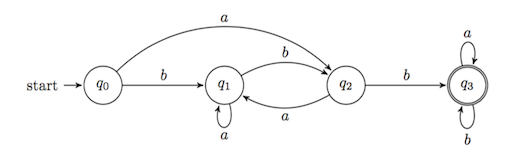
This diagram represents the DFA \(M=(Q, \Sigma, \delta, q_0, F)\), where
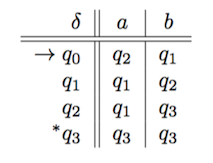
A string \(w\in \Sigma^*\) of length \(n\) is accepted by DFA \(M\) iff there exists a sequence of states \(r_0, r_1, \ldots, r_n\) such that
\(L(M)\), the language recognized by \(M\), is the set of all strings accepted by \(M\), i.e., \(L(M) = \{ w\in\Sigma^* : M \text{ accepts } w \}\).
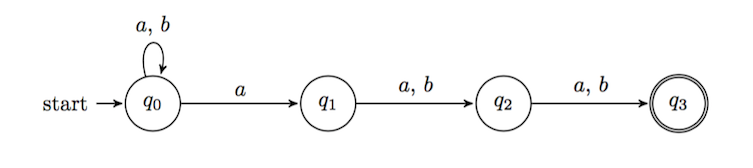
Exercise. Show that \(ab\) and \(babb\) are accepted by this machine but \(aab\) and \(bbaa\) are not.
We use comma-separated list of symbols as a shorthand for parallel edges, each labelled by a symbol in the list.
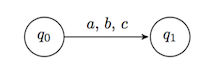
We may even use ellipsis for understood omitted symbols.
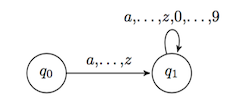
Sipser also uses \(\Sigma\) to represent a list of all symbols from the alphabet.
Let \(L_3\) be the language of all strings over \(\Sigma = \{a, b\}\) whose 3rd symbol from the right end is \(a\). Here is an NFA recognizing \(L_3\).
A DFA recognizing \(L_3\) will have to memorize the last 3 symbols seen, i.e., it needs \(2^3\) states (in general, \(|\Sigma|^3\) states).
Exercise. Design a DFA that recognizes \(L_3\).