Chomsky Normal Form
San Skulrattanakulchai
March 21, 2019
CNF is completely general
- Theorem. Every CFG has an equivalent CFG in CNF.
- Proof Idea. Step by step, we convert the current grammar to an equivalent one. Each step reduces some number of violations to CNF rules until none remains at the end.
Step 1: TERM
In Step 1, we make sure that if there is a rule \(A\to\alpha\) where \(\alpha \in (V\cup\Sigma)^*\) and \(|\alpha| \ge 2\), then \(\alpha\) contains no terminal.
For every symbol \(a\in\Sigma\) that occurs on the right side of some such rule, we do the followings
- introduce a new variable \(U_a\)
- replace every occurrence of \(a\) on every such right side by \(U_a\)
- add a rule \(U_a\to a\)
Performing this step to the given grammar (left) yields this equivalent grammar (right)
| \(S \to ASA \ |\ aB\) |
| \(A \to B \ |\ S\) |
| \(B \to b \ |\ \varepsilon\) |
|
| \(S \to ASA \ |\ U B\) |
| \(A \to B \ |\ S\) |
| \(B \to b \ |\ \varepsilon\) |
| \(U \to a\) |
|
Step 2: BIN
In Step 2, we eliminate all rules whose right side’s length is more than 2. We substitute any rule of the form \(A\to B_1B_2\dots B_k\), where \(k>2\), by these \(k-2\) rules
\(A\to B_1C_1\)
\(C_1\to B_2C_2\)
\(\qquad\vdots\)
\(C_{k-2}\to B_{k-1}B_k\)
(Note that \(C_1,\dots,C_{k-2}\) are new variables.)
Performing this step to the grammar from previous step (left) yields this equivalent grammar (right)
| \(S \to ASA \ |\ U B\) |
| \(A \to B \ |\ S\) |
| \(B \to b \ |\ \varepsilon\) |
| \(U \to a\) |
|
| \(S \to AC \ |\ U B\) |
| \(C \to SA\) |
| \(A \to B \ |\ S\) |
| \(B \to b \ |\ \varepsilon\) |
| \(U \to a\) |
|
Step 3: START
In Step 3, we eliminate all rules having the start variable on the right side. We first introduce a new variable \(S'\), then change all occurrences of \(S\) anywhere in any rule to \(S'\), and finally add a new rule \(S\to S'\).
Performing this step to our grammar from previous step (left), we get the new grammar (right)
| \(S \to AC \ |\ U B\) |
| \(C \to SA\) |
| \(A \to B \ |\ S\) |
| \(B \to b \ |\ \varepsilon\) |
| \(U \to a\) |
|
| \(S \to S'\) |
| \(S' \to AC \ |\ U B\) |
| \(C \to S'A\) |
| \(A \to B \ |\ S'\) |
| \(B \to b \ |\ \varepsilon\) |
| \(U \to a\) |
|
Step 4: DEL
A variable \(A\) is called nullable if \(A\Rightarrow^*\varepsilon\).
An \(\varepsilon\)-rule is a rule that has \(\varepsilon\) as its right side.
Step 4 has a number of substeps, whose purpose is to remove all forbidden \(\varepsilon\)-rules.
We find all nullable variables using this algorithm.
N := {A : the grammar has a rule A → ε};
while (there exists a rule A → B with B in N
but A not in N, or there exists a rule
A → BC with both B,C in N but A not in N)
do {
add A to N;
}
return N; // N is the set of all nullable variables
Step 4 continued
- For each rule whose right side has length 2 and has exactly one nullable variable \(A\), say \(X\to AY\) or \(X\to YA\), we add a rule \(X\to Y\) (unless \(X=Y\)).
- For each rule \(X\to AB\) where both \(A\) and \(B\) are nullable, we add rules \(X\to A\) (unless \(X=A\)) and \(X\to B\) (unless \(X=B\)). (Note that \(A\) and \(B\) may very well be the same. In that case, we need only add \(X\to A\) once.)
- Remove all \(\varepsilon\)-rules.
- Add rule \(S\to\varepsilon\) if \(S\) is nullable.
Step 4 continued
In the grammar from previous step (left), only \(A\) and \(B\) are nullable. Applying steps 4.2–4.5 to it results in the equivalent grammar on the right.
| \(S \to S'\) |
| \(S' \to AC \ |\ U B\) |
| \(C \to S'A\) |
| \(A \to B \ |\ S'\) |
| \(B \to b \ |\ \varepsilon\) |
| \(U \to a\) |
|
| \(S \to S'\) |
| \(S' \to AC\ |\ C \ |\ U B \ |\ U\) |
| \(C \to S'A \ |\ S'\) |
| \(A \to B \ |\ S'\) |
| \(B \to b\) |
| \(U \to a\) |
|
Step 5: UNIT
In Step 5, we eliminate all unit rules, i.e., those of the form \(A\to B\) where \(B\) is also a variable.
First, delete every rule of the form \(A\to A\) as they do not contribute anything to the generated language. (In fact, any time during our whole algorithm if we discover any such rule, we should delete it from the grammar.)
Next, create a directed graph showing all the unit rules. The vertices of the graph are the variables participating in some unit rule. There’s an edge from vertex \(A\) to vertex \(B\) if and only if the grammar has a unit rule \(A\to B\).
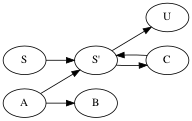
- On the right is the unit rules graph of our current grammar on the left
| \(S \to S'\) |
| \(S' \to AC\ |\ C \ |\ U B \ |\ U\) |
| \(C \to S'A \ |\ S'\) |
| \(A \to B \ |\ S'\) |
| \(B \to b\) |
| \(U \to a\) |
|
|
Step 5 continued
- Step 5 has two substeps
- The first substep gets rid of all cycles in the graphs.
- The second substep deletes vertices (and edges) from the graphs.
This first substep removes all cycles from the graph, and at the same time alters the grammer to maintain equivalence.
while (the graph has some cycle) do {
choose a cycle C;
let X be an arbitrary vertex in C;
for (each rule) do {
if (any vertex Y of cycle C appears in the rule
and Y is not equal to X)
then {
change every occurrence of Y in the rule to X;
}
}
contract the cycle C;
}
Step 5 continued
| \(S \to S'\) |
| \(S' \to AC\ |\ C \ |\ U B \ |\ U\) |
| \(C \to S'A \ |\ S'\) |
| \(A \to B \ |\ S'\) |
| \(B \to b\) |
| \(U \to a\) |
|
|
Our graph has one cycle
\(S' \to C \to S'\). Choosing
\(C\) as the name of the cycle soon to be contracted, we change every occurrence of
\(S'\) in any rule to
\(C\), then contract the cycle. It results in this grammar and graph:
| \(S \to C\) |
| \(C \to AC \ |\ U B \ |\ U \ |\ CA\) |
| \(A \to B \ |\ C\) |
| \(B \to b\) |
| \(U \to a\) |
|
|
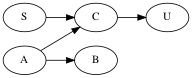
The graph no longer has any cycle. We move on to the next substep.
Step 5 continued
The second substep is to delete all edges of the graphs, and at the same time alters the grammer to maintain equivalence.
while (the graph has some vertex with entering edge) do {
let X be a vertex with some entering edge but no leaving edge;
delete X and all its entering edges from the graph;
for (each unit rule of the form A → X) do {
delete the rule A → X from the grammar;
for (each rule X → α) do
add rule A → α to the grammar;
}
}
Step 5 continued
Coming back to our grammar. We can either delete vertex
\(U\) or vertex
\(B\). Let’s choose
\(U\) as victim. We delete
\(U\) from the graph and alter the upper grammar
| \(S \to C\) |
| \(C \to AC \ |\ U B \ |\ U \ |\ CA\) |
| \(A \to B \ |\ C\) |
| \(B \to b\) |
| \(U \to a\) |
|
|
to get this grammar and graph
| \(S \to C\) |
| \(C \to AC \ |\ U B \ |\ a \ |\ CA\) |
| \(A \to B \ |\ C\) |
| \(B \to b\) |
| \(U \to a\) |
|
|
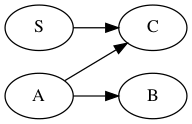
Step 5 continued
| \(S \to C\) |
| \(C \to AC \ |\ U B \ |\ a \ |\ CA\) |
| \(A \to B \ |\ C\) |
| \(B \to b\) |
| \(U \to a\) |
|
|
At this point we can delete either vertex
\(B\) or vertex
\(C\). Let’s choose
\(B\) as victim. We delete
\(B\) and alter the grammar to get the lower grammar and graph.
| \(S \to C\) |
| \(C \to AC \ |\ U B \ |\ a \ |\ CA\) |
| \(A \to b \ |\ C\) |
| \(B \to b\) |
| \(U \to a\) |
|
|
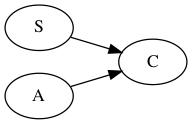
Step 5 continued
| \(S \to C\) |
| \(C \to AC \ |\ U B \ |\ a \ |\ CA\) |
| \(A \to b \ |\ C\) |
| \(B \to b\) |
| \(U \to a\) |
|
|
At this point \(C\) is the only vertex to be deleted. We delete it and alter the grammer to
| \(S \to AC\ |\ U B\ |\ a \ | \ CA\) |
| \(C \to AC\ |\ U B\ |\ a \ | \ CA\) |
| \(A \to b\ |\ AC \ |\ U B \ |\ a \ |\ CA\) |
| \(B \to b\) |
| \(U \to a\) |
|
The resulting graph now has no edge, and we are done! Above is the final grammar in CNF.